
我们的运维监控系统主要有三个功能:
-
之一个是故障报警;
-
第二个是故障分析和定位;
-
第三个是自动化策略。
今天我们的分享主题,主要有以下三部分:
之一个就是监控数据收集轻量化;
第二个是微信数据监控的发展过程;
第三个海量监控分析下的数据存储设计思路。
一、监控数据收集轻量化
先看一下常见数据收集流程,一般常见的采集流程来说从日志里面采集,然后本地汇总打包,再发到全局服务器里面汇总。
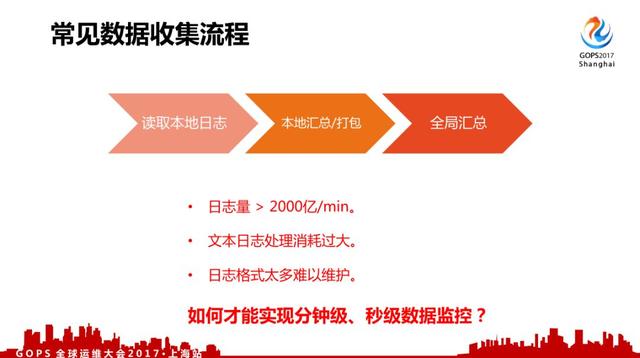
但是对于微信来说,200w/min调用量产生的是2000亿/min的监控数据上报,这个可能还是比较保守的估计。
早期我们使用过自定义文本类型日志上报,但由于业务及后台服务非常多,日志格式增长非常快,难以持续进行维护,而且不管是CPU、 *** 、存储、统计都出现非常大的压力,难以保证监控系统本身的稳定。
为了实现稳定的分钟级、甚至秒级的数据监控,我们进行了一系列改造。
对于我们内部监控数据处理分为两个步骤:
我们对数据进行分类,在我们内部来说有三种数据:
之一是实时故障监控分析;
第二种是非实时数据统计,比如说业务报表等;
第三种是单用户异常分析,比如说用户一个报障过来还要单独对用户故障进行分析。
下面先简单介绍一下非实时数据统计及单用户异常分析,再重点介绍实时监控数据的处理。
1.1、非实时数据
对于非实时数据来说,我们有一个配置管理页面。
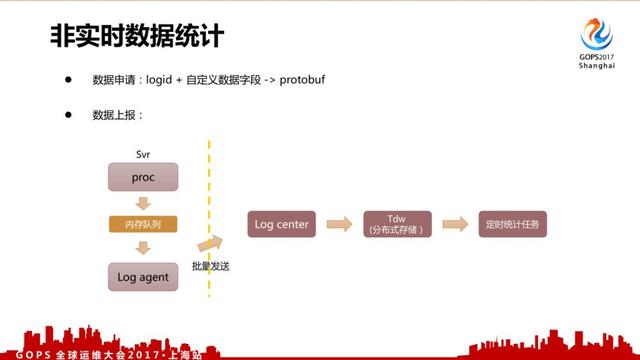
用户在上报的时候会先申请 logid + 自定义数据字段,上报并非使用写日志文件的方式,而是采用共享内存队列、批量打包发送的方式减少磁盘IO、日志服务器的调用压力。统计使用分布式统计,目前已经是常规做法。
1.2、单用户异常分析
对于单个用户异常分析来说,我们关注的是异常,所以上报路径跟刚才非实时的路径比较相近。
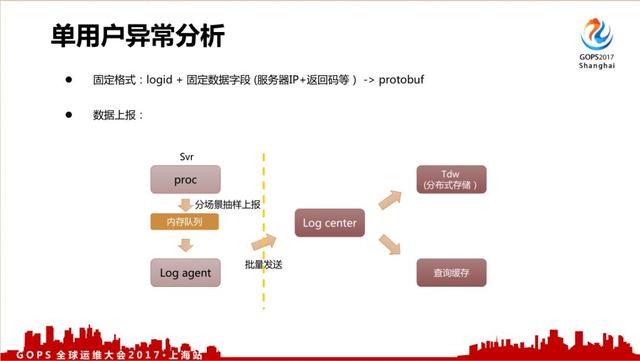
采用固定的格式: logid + 固定数据字段(服务器IP+返回码等),数据上报量比刚才的非实时日志还要大很多,所以我们是抽样上报的,除了把数据存入到Tdw分布式存储里面,还会把它转发到另外一个缓存里面进行一个查询缓存。
1.3、实时监控数据
实时监控数据是重点分享的部分,这部分数据也是2000亿/min日志上报中的绝大多数。
为了实现分方位的监控,我们的实时监控数据也有很多种类型,其格式、来源、统计方式都有差异,为了实现快速稳定的数据监控,我们对数据进行了分类,然后针对性的对各类数据进行简化、统一数据格式,再对简化后的数据采取更优的数据处理策略。
对我们数据来说,我们觉得有下面几种:
1.3.1、后台数据监控
对于我们后台数据监控来说,我们觉得按层次来说分成四类,每种有不同的格式和上报方式:
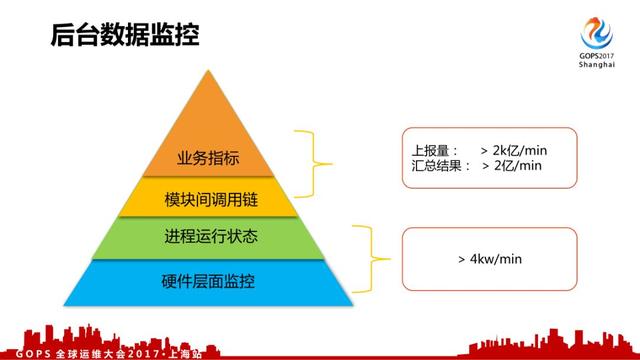
1、硬件层面监控,比如服务器负载、CPU、内存、IO、 *** 流量等。
2、进程运行状态,比如说消耗的内存、CPU、IO等。
3、模块间调用链,各个模块、机器间的调用信息,是故障定位的关键数据之一。
4、业务指标,业务总体层面上的数据监控。
不同类型的数据简化成如下格式,方便对数据进行处理。
其中底下两层都用IP+Key的格式,后来出现了容器后,使用ContainerID、IP、Key的格式。
而模块调用信息,又把模块的被调总体信息抽出来,跟业务指标共用ID、Key的数据格式。








